
返回 
开发者工具
Firecrawl
Firecrawl 是面向 AI 代理和开发者的 Web 抓取、搜索、映射与交互 API,提供 LLM‑ready 的 Markdown、JSON、截图等结构化数据,帮助快速构建基于真实网页信息的智能应用。
产品简介
Firecrawl 是面向 AI 代理和开发者的 Web 抓取、搜索、映射与交互 API,提供 LLM‑ready 的 Markdown、JSON、截图等结构化数据,帮助快速构建基于真实网页信息的智能应用。
产品截图
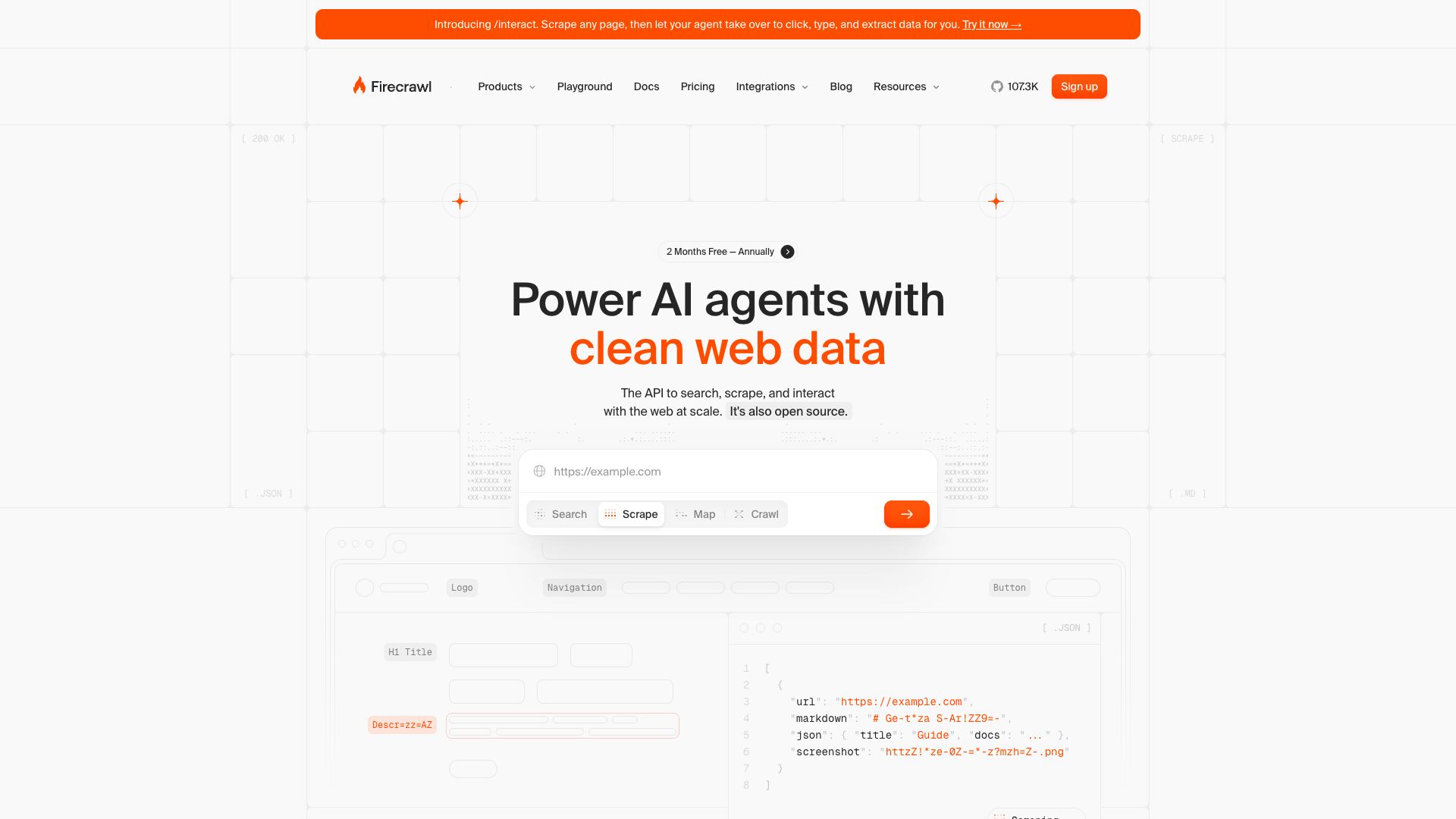
详细介绍
产品概述
Firecrawl 是一套面向人工智能应用与开发者的全栈 Web 数据获取平台。它通过统一的 API 将整个互联网转化为干净的、适配大语言模型(LLM)的 Markdown 或结构化数据,支持搜索、抓取、站点映射、爬取以及交互式浏览等功能,帮助 AI 代理、聊天机器人、研究平台等快速获取实时网页内容。
核心功能与特点
- Scrape:一键返回页面的 Markdown、JSON、截图等多种格式;支持 PDF、DOCX 等媒体文件解析。
- Search:在全网搜索并直接返回完整内容,省去二次抓取步骤。
- Map:自动发现站点所有可访问子页面,生成站点地图。
- Interact:通过 AI 提示或代码指令在页面上点击、滚动、输入后再抓取,实现动态交互抓取。
- 多语言 SDK:提供 Python、Node.js、cURL、CLI 等多种集成方式。
- 高覆盖率与可靠性:覆盖约 96% 的网页,包括大量 JS‑heavy 页面;智能等待、旋转代理、速率限制等机制保证抓取成功率。
- 性能优秀:P95 延迟 3.4 秒,远快于传统 Puppeteer 等方案。
- 开源+托管:核心代码开源,托管版提供专属 Fire‑engine、仪表盘、缓存与安全防护。
- 零配置:自动处理代理、反爬、缓存等复杂细节,用户只需调用 API 即可。
优势
- LLM‑ready 数据:直接输出干净的 Markdown,降低 Token 消耗,提升下游模型效果。
- 速度与可靠性:基准测试显示比 Puppeteer 高出约 30% 以上,且对动态内容支持完整。
- 易于集成:多语言 SDK 与常见工具(Claude、Cursor、Windsurf 等)即插即用。
- 可扩展定价:免费 500 页起步,提供 Hobby、Standard、Growth、Scale 等层级,满足从个人项目到企业级大规模抓取的需求。
- 社区与透明度:开源仓库活跃,频繁发布功能迭代,拥有 10 万+ GitHub Star,受到 80,000+ 家企业信任。
- 安全合规:遵循 robots.txt、提供 SSO、SOC 2 等企业安全保障。
应用场景
- AI 助手与聊天机器人:实时为对话提供最新网页资讯、答案检索。
- 营销与销售线索 enrichment:从公司官网、目录页批量提取联系人、产品信息,提升 CRM 数据质量。
- 研究与情报:自动抓取学术论文、行业报告、竞争对手页面,生成结构化研究数据。
- SEO 与内容聚合:批量抓取竞争网站结构、关键词,支持内容审计与优化。
- AI 平台与插件:作为底层数据源嵌入代码编辑器、MCP 客户端,为开发者提供“一键网页数据”能力。
- 企业级数据管道:在大规模爬取、定时同步、缓存更新等场景下,构建持续的网页数据供应链。
相关工具

